Sweep using W&B
In the spring of 2022, I took the course 02460: Advanced Machine Learning at the Technical University of Denmark. In the course, we had a project about regularization of graph neural networks.
Here, our model loss consisted of two terms:
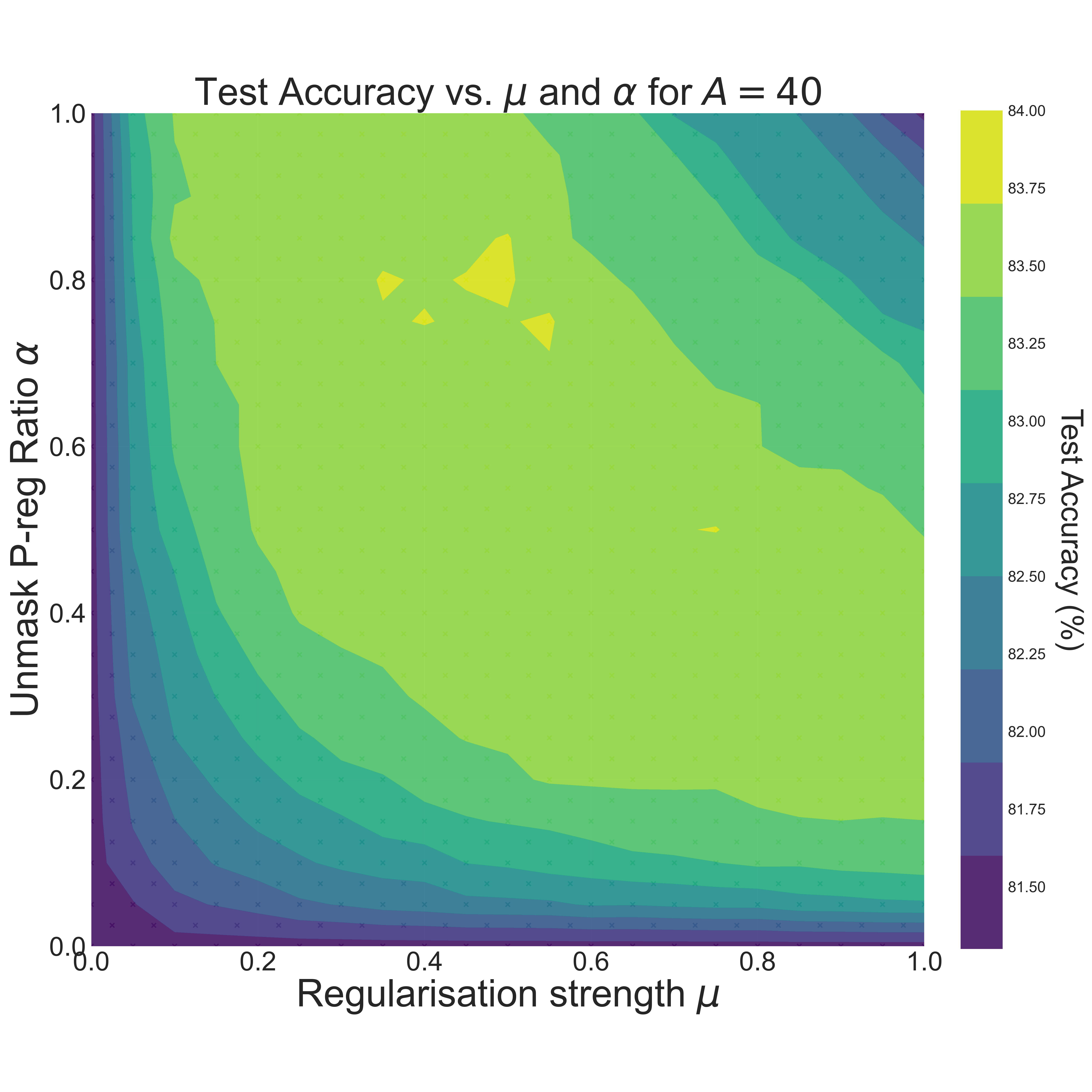
Essentially, a fraction \(\alpha\) of the training examples were masked and regularized with regularization strength \(\mu\) using the propagation loss introduced in Rethinking Graph Regularization for Graph Neural Networks.
Given an \(n \times n\) grid of \((\mu, \alpha)\) values, we wanted to create the following table:
| \(\mu\) | \(\alpha\) | Test accuracy (mean) | Test accuracy (std) |
|---|---|---|---|
| \(\mu_1\) | \(\alpha_1\) | ... | ... |
| \(\mu_1\) | \(\alpha_2\) | ... | ... |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(\mu_2\) | \(\alpha_1\) | ... | ... |
| \(\mu_2\) | \(\alpha_2\) | ... | ... |
| \(\vdots\) | \(\vdots\) | \(\vdots\) | \(\vdots\) |
| \(\mu_n\) | \(\alpha_n\) | ... | ... |
where the test accuracy was calculated for 10 different initializations of the model, trained until convergence. Now, this would have been pretty difficult to keep track of, since we wanted the \((\mu, \alpha)\)-grid to be rather large. Entering Weights & Biases and their sweep feature!

Having set up our training script, a yaml file was all that was needed to run the sweep. For example, with a \(3 \times 3\) grid with 5 different initializations, the yaml file would look like this:
method: grid
parameters:
mu:
values:
- 0.1
- 0.2
- 0.3
unmask-alpha:
values:
- 0.1
- 0.2
- 0.3
seed:
values:
- 1
- 2
- 3
- 4
- 5
program: main.py
Each \((\mu, \alpha, \text{seed})\) combination would then give a test accuracy, and then the mean and standard deviations could be calculated.
The best thing with sweep is that multiple agents can work at the same time, so if we submitted 5 GPU jobs, we would have 5 agents working on the \((\mu, \alpha, \text{seed})\)-sweep with W&B doing the bookkeeping.
To produce the figure below, a total of 4000 models were trained. Without W&B, this would have been a nightmare to keep track of!
Thanks for reading! Next time you want to do a lot of ML experiments, I definitely recommend giving W&B's sweep functionality a try. It's a bit of a hassle to set up, but it's definitely worth it once you have to train a lot of models.
If you want to check out the code for our project, you can find it here.